Graph-augmented search
Semantic retrieval is combined with knowledge graph relationships and keyword search so recall reflects meaning, explicit terms, and connected concepts instead of relying on one signal alone.
Infrastructure / Desktop
H.I.V.E. turns documents, conversations, logs, and scenarios into analyzable memory. Run it 100% local with Ollama or mix in OpenAI, Anthropic, Google, Azure, and Grok. Cartridge isolation, tiered storage, deterministic recall, and conflict resolution keep context useful without giving up control.
Development alphaTarget: late this yearAir-gapped or cloud
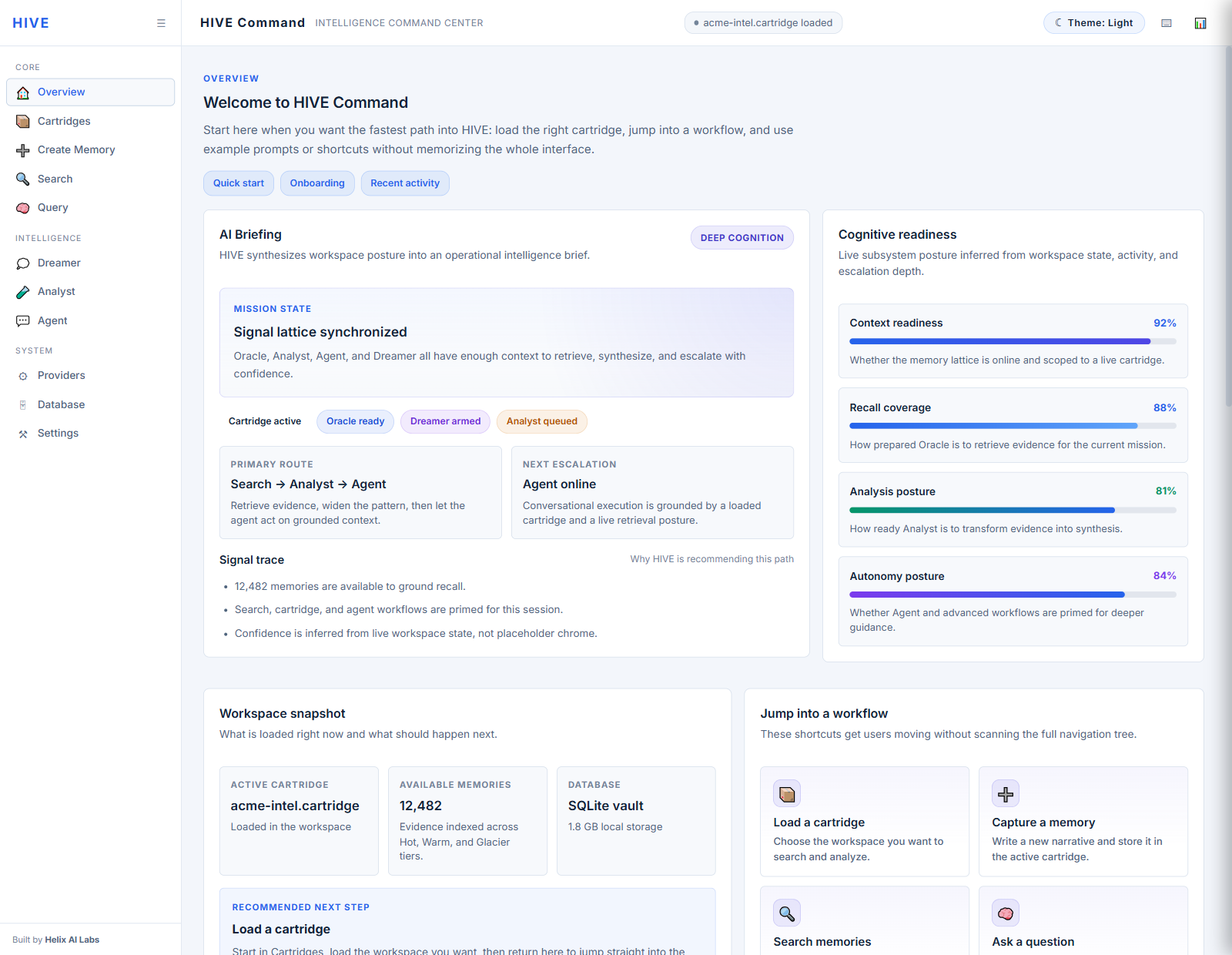
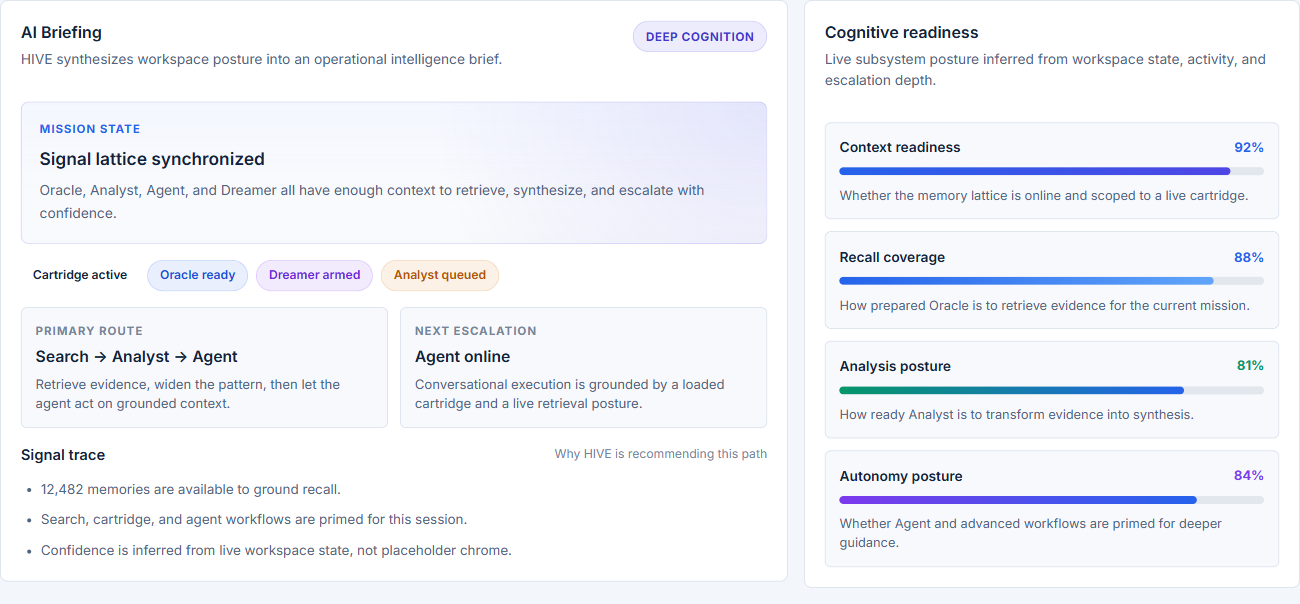
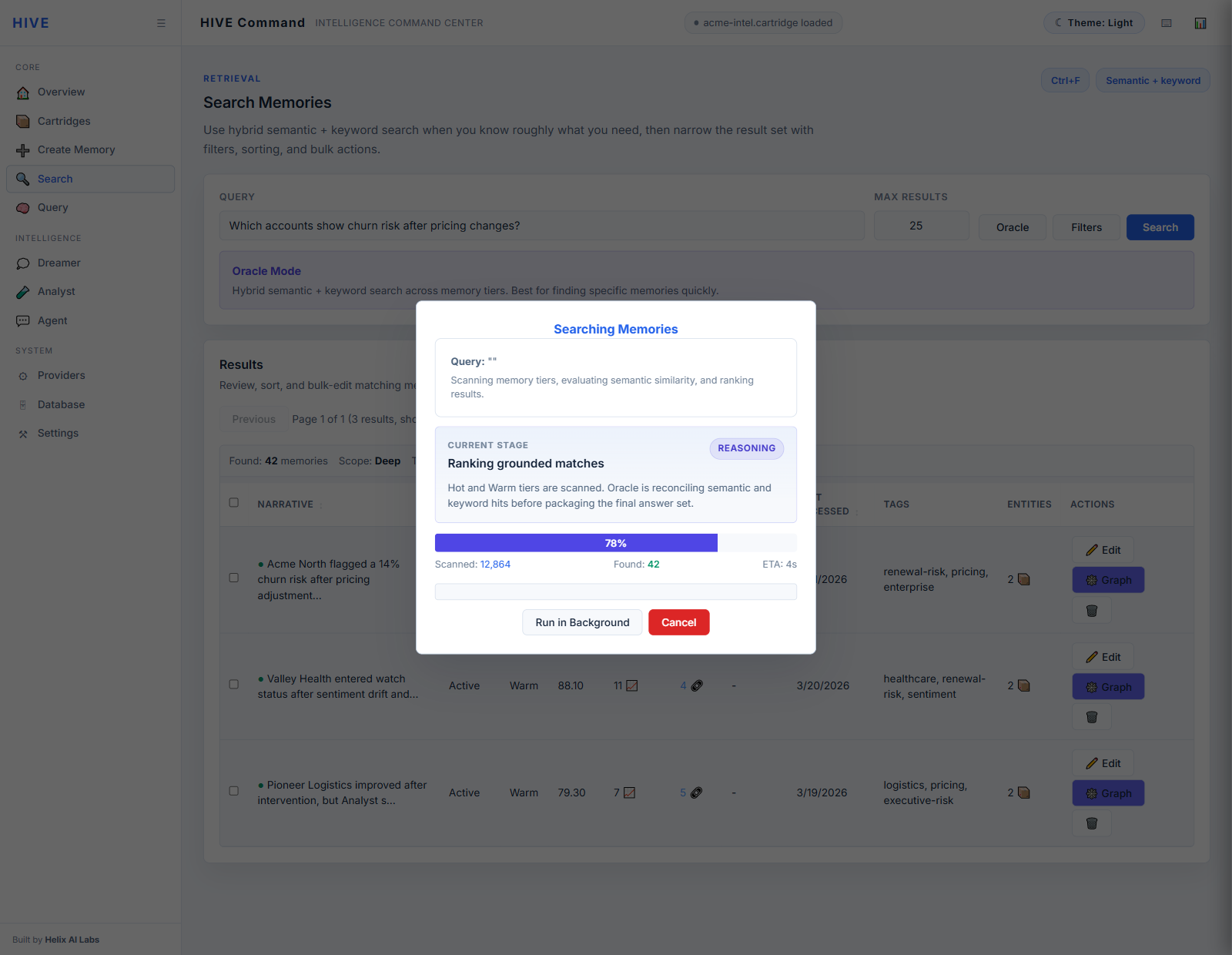
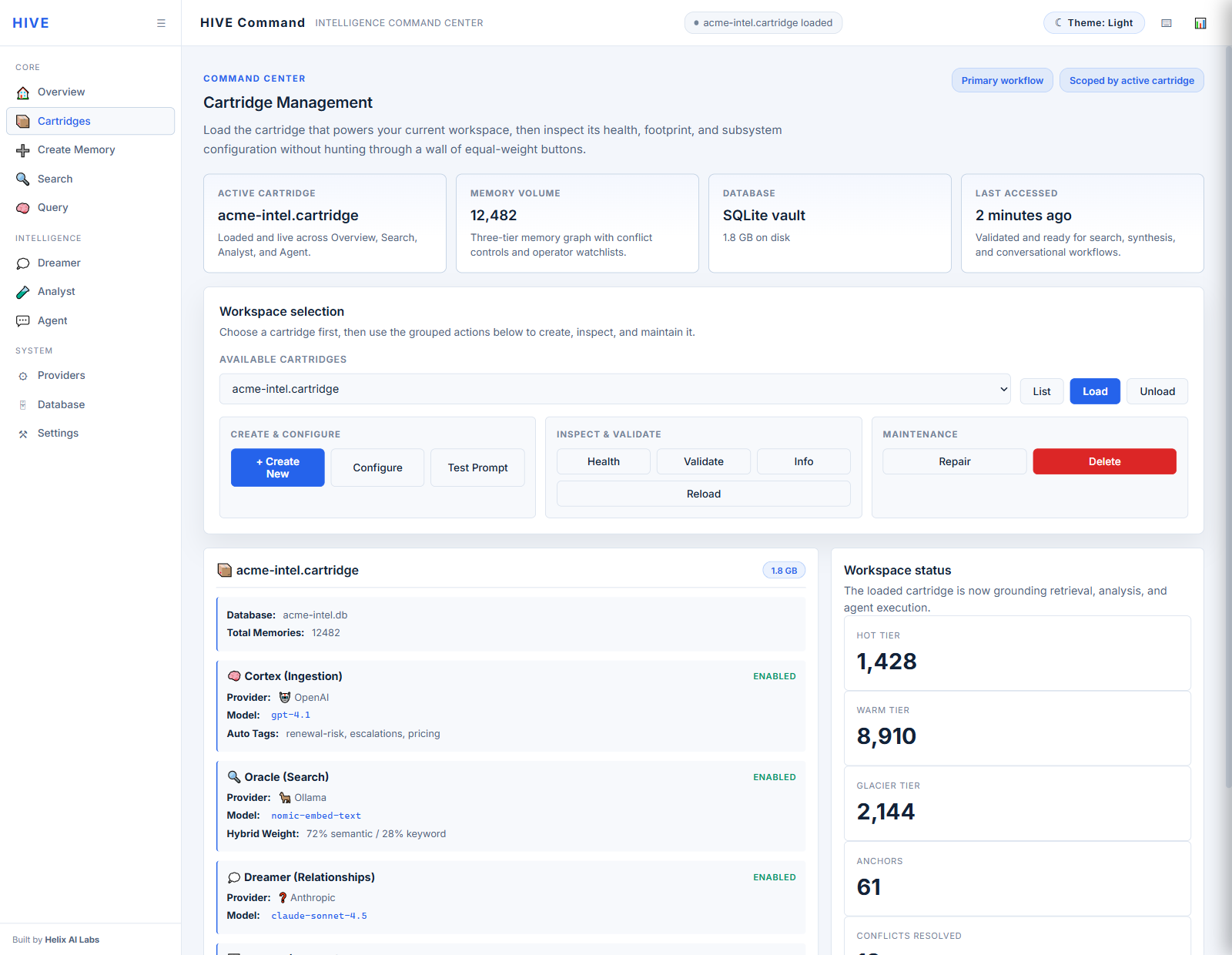
Product walkthrough
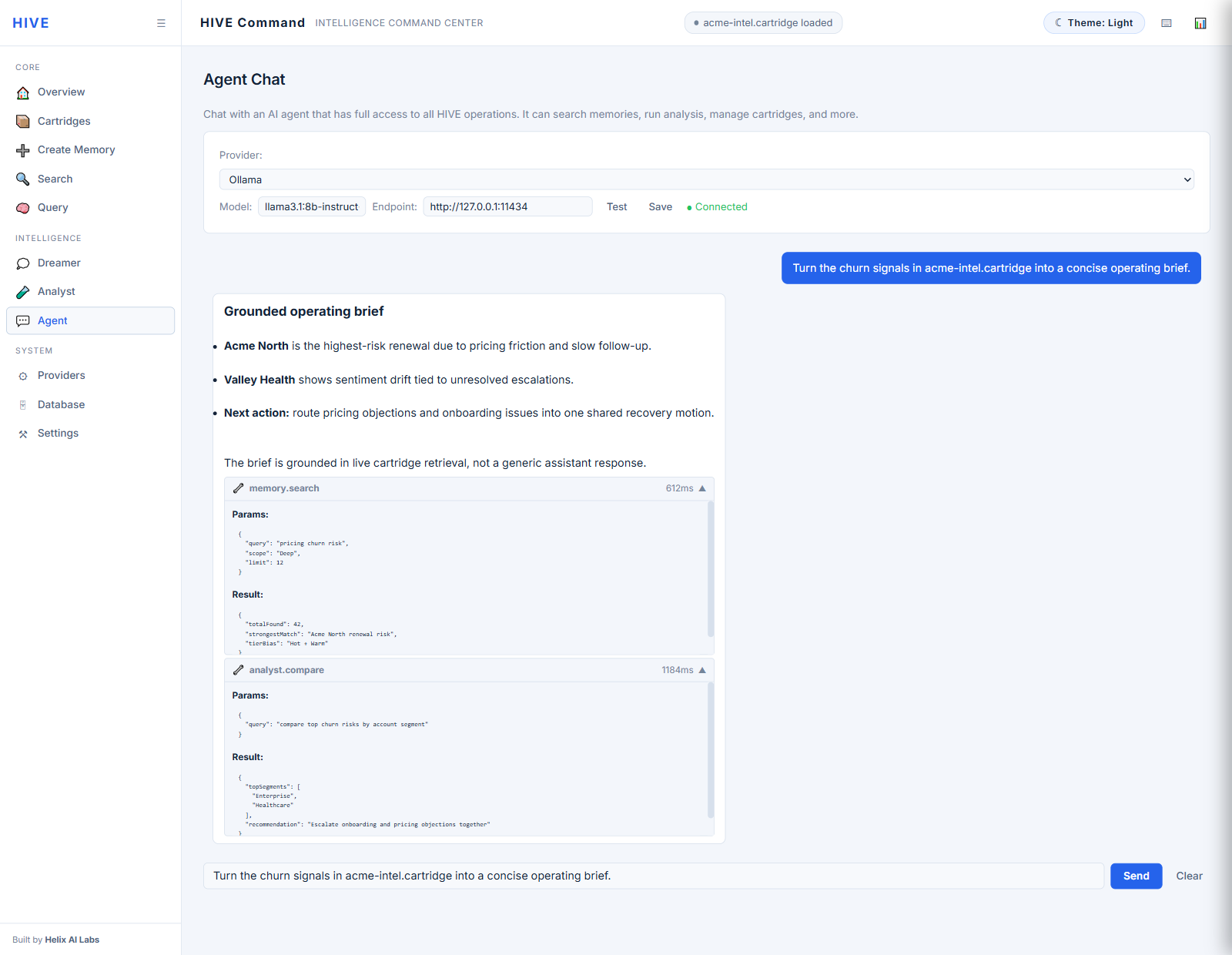
Actual captures from the current HIVE Command Center. This is the proof layer: the command overview, AI briefing posture, transparent search progress, loaded cartridge control, and grounded agent workflow that make H.I.V.E. feel like a real intelligence console instead of a diagram.
These are real HIVE Command Center captures. Select a surface, then open it full size for a closer read on the loaded-state UI.
Memory primitives
H.I.V.E. is designed for memory that needs to survive beyond a single session and remain inspectable enough for production, research, and secure deployment paths.
Semantic retrieval is combined with knowledge graph relationships and keyword search so recall reflects meaning, explicit terms, and connected concepts instead of relying on one signal alone.
Importance rises and falls based on recency, frequency, and utility. Hot, Warm, and Glacier tiers let frequently used memory stay fast while colder material remains available without bloating the working set.
Every data source can run inside its own cartridge with dedicated databases, prompts, metadata, and conflict rules, keeping domain logic separated instead of collapsing everything into one giant memory pile.
Cortex turns raw text into structured intelligence through synthesis, entity extraction, and tagging. The same pipeline can target local Ollama models or major cloud providers depending on deployment policy.
Analyst runs long-form questions over memory data with background jobs, result caching, sampling controls, and cost estimation so expensive reasoning stays deliberate.
Dreamer discovers links between memories over time and records confidence so the graph becomes a usable retrieval layer instead of decorative metadata.
SQLite, SQL Server, Azure SQL, Kusto, and Dataverse storage backends give teams a path from zero-config local installs to enterprise deployment while keeping the system usable in disconnected environments.
Query caching, explainable ranking, and four conflict strategies—AutoSupersede, LLM Evaluation, Human Review, and Disabled—keep retrieval reproducible and contradictions visible instead of silently overwritten.
Architecture
H.I.V.E. keeps ingestion, storage, retrieval, scoring, and extension layers separate so new data sources and deployment constraints do not turn into one tangled subsystem.
Cortex performs synthesis, entity extraction, and tagging. Vault stores the resulting memory through tiered storage and pluggable backends such as SQLite, SQL Server, Azure SQL, Kusto, and Dataverse.
Oracle combines semantic, keyword, and relationship retrieval. Heuristics applies gravity scoring, tier management, and ranking behavior so recall stays explainable.
Dreamer grows the graph, Arbiter resolves contradictions, and Analyst handles higher-order analysis over the memory corpus without blocking the main retrieval path.
Cartridges isolate sources, prompts, databases, and metadata schemas. Cells provide the source-specific processors for Reddit, LinkedIn, CSV, sentiment, exports, and any custom domain adapter you need.
Deployment patterns
H.I.V.E. can sit underneath agent systems, document workflows, research environments, and operational data streams without forcing them into the same shape.
Give agent systems persistent memory that can survive across sessions and stay isolated per role, tenant, or objective.
Turn legal contracts, research papers, technical specs, and policies into queryable knowledge rather than static archives.
Ingest incidents, support tickets, operations notes, or security events and let the memory layer surface comparable cases and hidden patterns.
Make unstructured logs more readable through synthesis, anomaly detection, and natural-language investigation without flattening everything into one static dashboard.
Support academic or institutional research by tracking hypotheses, surfacing related work, and making evolving knowledge easier to query.
Unify Slack, Confluence, SharePoint, exports, and other internal systems while preserving per-source rules and access boundaries.
Deployment planning
H.I.V.E. is in development alpha for teams that need memory infrastructure to remain private, inspectable, and portable across local, enterprise, and air-gapped environments.